ReasonField Lab
VirtusLab Group Company
hello@reasonfieldlab.com
ReasonField Lab 2024, All Rights Reserved


The deployment of large language models (LLMs) on production systems can face several challenges, and identifying bottlenecks is crucial for optimizing their performance. Some common bottlenecks in LLM deployment on production include:
Addressing these bottlenecks requires a combination of hardware optimization, model architecture tuning, and efficient deployment strategies. Additionally, it is crucial to consider the specific requirements and constraints of the production environment when deploying LLMs. In the article below I will cover the most important aspects of addressing those challenges.
Boosting the performance of the deployed model should always start with problem identification. As mentioned above there are multiple challenges that we might encounter and we should understand first which of those are the most important for us. If we struggle at first with fitting the model on the GPU, obviously we will start with memory optimization. Here we can try model quantization to float16 or float8, or load model layers during the inference time one by one. When the output is calculated, the layer is pulled back off the GPU and the next layer will be sent from the CPU to the GPU. This way it is possible to run any size model on your system, as long as the largest layer is capable of fitting on your GPU. The feature is implemented in the accelerate library.
If we already have the model running we can focus on other challenges. If we have only a few users in a system or many users with high throughput, but response latency is high, we might want to implement response streaming or optimize inference time. We can achieve that by using Flash-Attention layers, setting up max beam width, removing input padding, using root-mean-square-normalization layers (RMS norm) instead of instance normalization, using GEneral Matrix to Matrix Multiplication (GEMM) or horizontally fusing of GatedMLP layers. Quantization also can boost model inference speed, but only if quantized kernels are used. Most of the quantization methods will only reduce model size, but not boost inference speed. It is also worth mentioning that not every GPU architecture supports all precision types. Therefore decisions about quantization should be made based on the knowledge of the target GPU architecture. GPU-precision support matrix for the most common NVIDIA GPUs can be found here.
If we already have low latency but struggle with throughput, so the number of users your system can serve simultaneously we might want to implement cellular batching, iteration-level scheduling, or paged attention. The first two solutions allow for the inclusion of newly arrived requests and the return of newly completed requests at each iteration of the token generation loop. The paged attention is a smart GPU memory management system, that minimizes memory fragmentation and at the same time speeds up inference by caching the KV.
Regardless of the problem, I always like to start with code profiling, as other weird things might happen that influence the system. For example, when profiling an LLM code a few months ago, I found that the code was trying to load the model in bfloat16 precision on Tesla T4, which does not support bfloat16 and therefore it was rolling back to float32 resulting in x2 as much memory usage. Also such a simple trick, as updating the CUDA version from 11.7 to 12.3 might speed up the model by 20%.
It is a great tool for LLM optimization. It implements all the above-mentioned inference speed and memory usage optimization features. To start with TensorRT-LLM please follow the official installation instructions in the GitHub repository. The main step in boosting the model with TRT-LLM is converting the model. The conversion can be done with the following command line for the TRT-LLM version below 8.0:
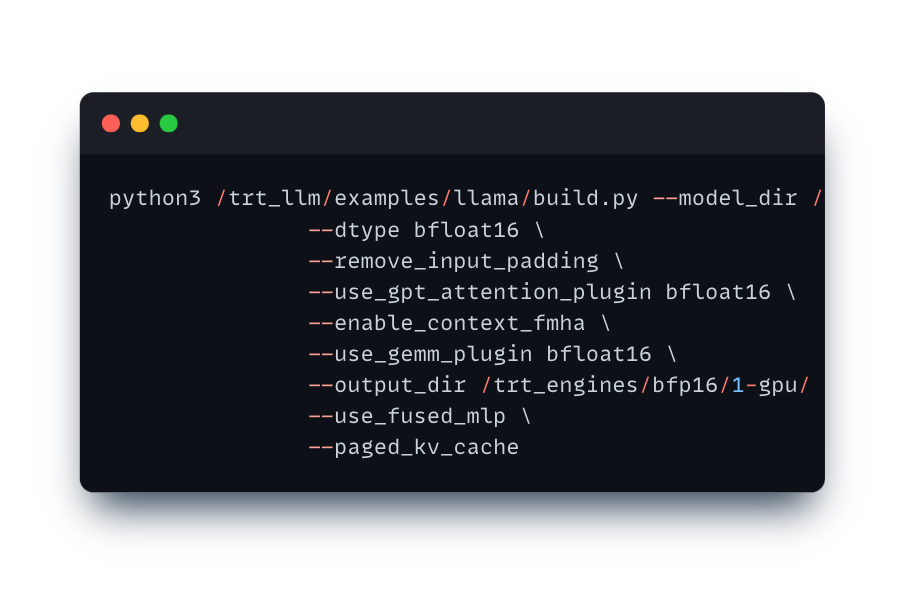
For newer versions, the engine generation procedure consists of 2 steps:
.png)
.png)
After successfully creating engine files, the inference test can be run with the python3 /trt_llm/examples/run.py script.
A naive batching strategy would either make earlier requests wait for later ones or delay the incoming requests until earlier ones finish, leading to significant queueing delays. TensorRT-LLM relies on BatchManager, to support in-flight batching on request. By setting the flag -use_inflight_batching in the model conversion procedure, we make the model capable of incorporating new requests as part of the batch to already processed requests. Instead of waiting for the previous request to complete, we can add a new request to the batch on the iteration level, so after a new token is generated for the current iteration. This way the throughput is increased significantly with only a small computation and memory overhead.
Inflight batching increases the model throughout but creates a problem of increased memory usage which comes with a large batch size. Existing systems face challenges because the memory allocated for key-value cache (KV cache) in each request is large and changes in size dynamically. Inefficient management of this memory can lead to significant waste due to fragmentation and unnecessary duplication, ultimately restricting the batch size that the system can handle effectively. Here comes Paged Attention, an algorithm inspired by the classical virtual memory and paging techniques in operating systems. Instead of allocating memory for the KV cache as a continuous block in memory, it splits the KV cache into smaller blocks that can be allocated in a non-continuous way. It further adds logic for sharing KV cache blocks among and within requests. As a result, we can build an LLM serving system that achieves near-zero waste in KV cache memory and flexible sharing of KV cache within and across requests. When using the TensorRT inflight batching the paged attention has to be used as well. PaggedAttention can be turned on with the flag --paged_kv_cache. It is worth mentioning, that the paged KV cache is allocated upfront in the TensorRT implementation, not like described in a paper, on demand. Therefore we need circa 60% more VRAM memory, which is required by the model. The exact size of allocated memory for the KV cache depends on the batch size and max input/output prompts length and, eventually on max number of generated tokens.
Triton is a tool for model serving. It supports TensorRT-LLM integration using TensorRT-LLM-backend. When deploying TensorRT-LLM with Triton it is important to match particular versions. For example, the Triton 24.01 server container image comes with TensorRT-LLM 7.1. Using different code versions for compiling models to the TensorRT engine will result in errors during inference. Quite handy might be using pre-build docker images, with the TenroRT-LLM-backend part already installed. All available images can be found on the Triton NGC page.
For the purpose of model-serving, we need to define 4 directories, following the structure presented in Figure 1.
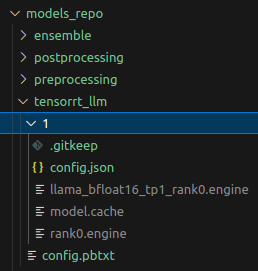
Pbtxt files contain information about model inputs/outputs, their shape, and type, plus some hyperparameters if applicable. The must-have other hyperparameters are batch size and decoupled boolean. If set to False, the model will return exactly one response for each request.
Each subfolder starts with a number, indicating the model/code version. Inside the folder can be placed a model checkpoint or Python script. The Python script will be used for execution, according to the ensemble strategy. The model checkpoint will be loaded automatically by the server. More about the Triton model repository can be read here.
Triton comes also with a handy model analyzer, which can recommend the Triton server parameters and hardware setup to achieve the highest throughput and lowest latency. For example, it can recommend the optimal number of instances or batch size.
After creating the Triton model repository, the Triton server can be run with:
.png)
Or if running with a docker container:
.png)
In the article, we learned about many great tools and libraries for LLMs' efficient deployment, versioning, and monitoring. If you want to learn more, I encourage you to read more about the Triton inference server here or here. And if you still struggle to make your model efficient, please feel free to contact us. We will be happy to help you.